



들어가며생각해보자1. 꼭 필요한 태스크만 수행하기2. 디팬던시 체인을 고려한 패키지 분리3. 수행한 적 있는 테스크는 수행하지 말기4. 병렬/분산으로 태스크를 수행하기5. 레포 크기 줄이기와 디팬던시 캐싱 전략 세우기결론
들어가며
ZEP은 현재 클라이언트의 모든 코드를 모노레포로 전환하여 관리하고 있습니다. 이를 통해 개발자들은 더 일관적인 개발 흐름과 유연한 오너십을 갖게 되었고 제품에 빠르고 안정적으로 피드백을 반영할 수 있게 되었습니다. 모노레포는 현재 개발 운영에대한 하나의 트렌드가 되었으며, 많은 개발자들이 이를 적용하고 있습니다. 모노레포는 많은 장점을 가지고 있지만, 그 장점을 활용하기 위해서는 잘 관리하고 설정해야 한다는 것이 중요합니다.
모노레포를 잘 구성하고 운영하기 위해서는 많은 고민과 노력이 필요합니다. 패키지의 수가 많지 않고 디팬던시가 복잡하지 않은 경우는 괜찮지만, 레포의 크기가 커지고 협업하는 인원이 늘어날수록, 특히 최적화되지 않은 CI/CD파이프라인에 기하급수적으로 병목이 발생 하게 됩니다.

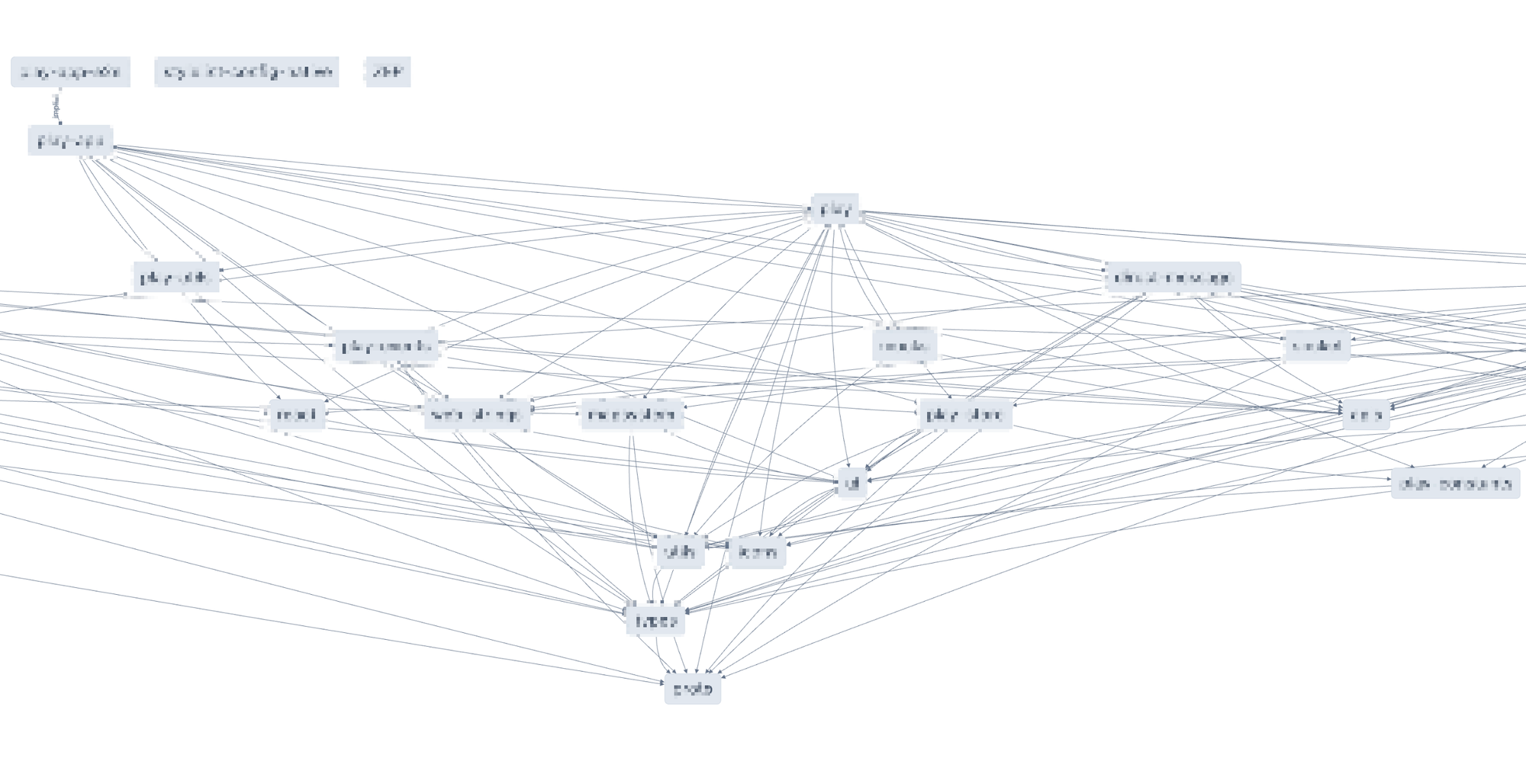
실제 ZEP 클라이언트 프로젝트의 의존성 그래프를 가져왔습니다. 그래프는 정말 복잡하게 얽혀 있습니다. 특정 패키지가 업데이트되면 해당 패키지에 의존하는 모든 패키지가 영향을 받습니다. 즉, A 패키지가 업데이트되면 A를 의존하는 B, C 및 모든 앱들이 다시 테스트 및 빌드되어야 할 수 있습니다. 현실에서는 코드 한 줄 추가할 때마다 배포를 위해 수십 분을 기다려야 할 수 있으므로 빠르고 유기적인 개발 프로세스를 가져가기 힘들게 되고 모든 화살은 모노레포에게 향하게 될 수 있습니다.
ZEP 프론트엔드 팀에서도 비슷한 상황이 발생했습니다. 파이프라인의 시간이 길어지면서 실제 배포까지 걸리는 시간이 30분이 넘어갔고 급한경우 파이프라인을 무시하고 강제로 병합하거나 배포하는 경우도 발생하였습니다.


따라서 몇가지 간단한 개선 작업을 진행하였고 결과적으로 파이프라인 시간을 약 2~5배 정도 줄일 수 있었습니다.
생각해보자
우선 모노레포 툴링도 많은 방법이 존재하고 CI/CD 또한 수 많은 환경이 존재합니다. 예를들면 github을 사용하고 actions를 사용했을 때, 모노레포 툴이 제공하는 플러그인을 사용 할 수 있는 환경일 때, Turborepo와 Vercel을 사용했을 때, 패키지 매니저를 무엇을 사용하느냐 등등에 따라 훨씬 쉽고 효과적으로 관리가 가능합니다. 따라서 우리의 사례는 따라하는게 아닌 각자의 환경에 맞는 고민과 방향성에 도움이 되었으면 좋겠습니다!
(참고로 우리의 환경은 외부의 툴을 사용못하고 오로지 Bitbucket pipeline을 사용하여야 하고 Nx로 모노레포 툴링을 하는 환경입니다! 제발 github 쓰세요! actions 쓰세요! CircleCI쓰세요!)
1. 꼭 필요한 태스크만 수행하기
CI/CD 파이프라인에서 꼭 필요한 태스크만 수행하는 것은 시간을 단축하는 가장 기본적인 방법 중 하나입니다. 불필요한 태스크를 건너뛰고 필요한 태스크만 실행하면 빌드 시간을 대폭 줄일 수 있습니다. 이를 위해서는 당연히 어떤 태스크가 필요한지 파악하고, 필요 없는 태스크는 제외해야 합니다.
우리가 모노레포 관리 도구 (예: Nx, Turborepo 등)의 도움을 받아야 하는 가장 큰 부분중 하나는 툴을 이용하여 패키지 간 의존성을 자동으로 분석한다거나, 패키지 간의 의존성을 일관되게 관리 하여 필요한(영향을 받는) 패키지만 파악하고 해당 테스크를 수행하는 것입니다.
Nx의 경우 affected 명령어를 사용하여 특정 브랜치 혹은 커밋(SHA)와 비교하여 실제로 어떤 패키지들이 영향을 받는지 파악하여 태스크를 수행할 수 있습니다.
PR의 경우 PR target 브랜치와 와 현재 브랜치를 비교합니다.
pull-requests: '**': - step: name: PR CI caches: - node-modules - cache... script: ... - npx nx affected --target=lint --base=origin/$BITBUCKET_PR_DESTINATION_BRANCH --head=$BITBUCKET_BRANCH --parallel=3 - npx nx affected --target=test --base=origin/$BITBUCKET_PR_DESTINATION_BRANCH --head=$BITBUCKET_BRANCH --parallel=3 - npx nx affected --target=stylelint --base=origin/$BITBUCKET_PR_DESTINATION_BRANCH --head=$BITBUCKET_BRANCH --parallel=3 - npx nx affected --target=build --base=origin/$BITBUCKET_PR_DESTINATION_BRANCH --head=$BITBUCKET_BRANCH --parallel=3

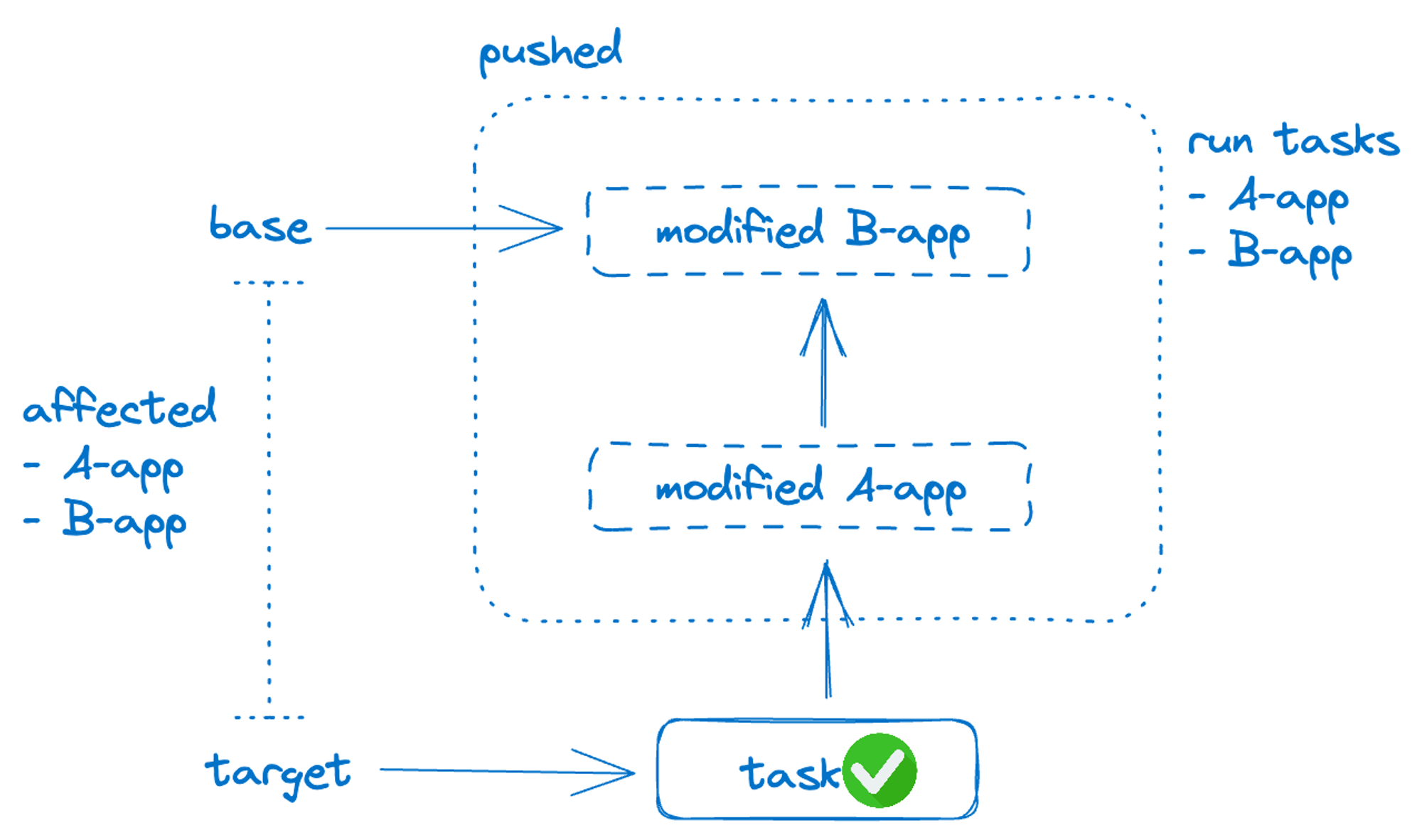

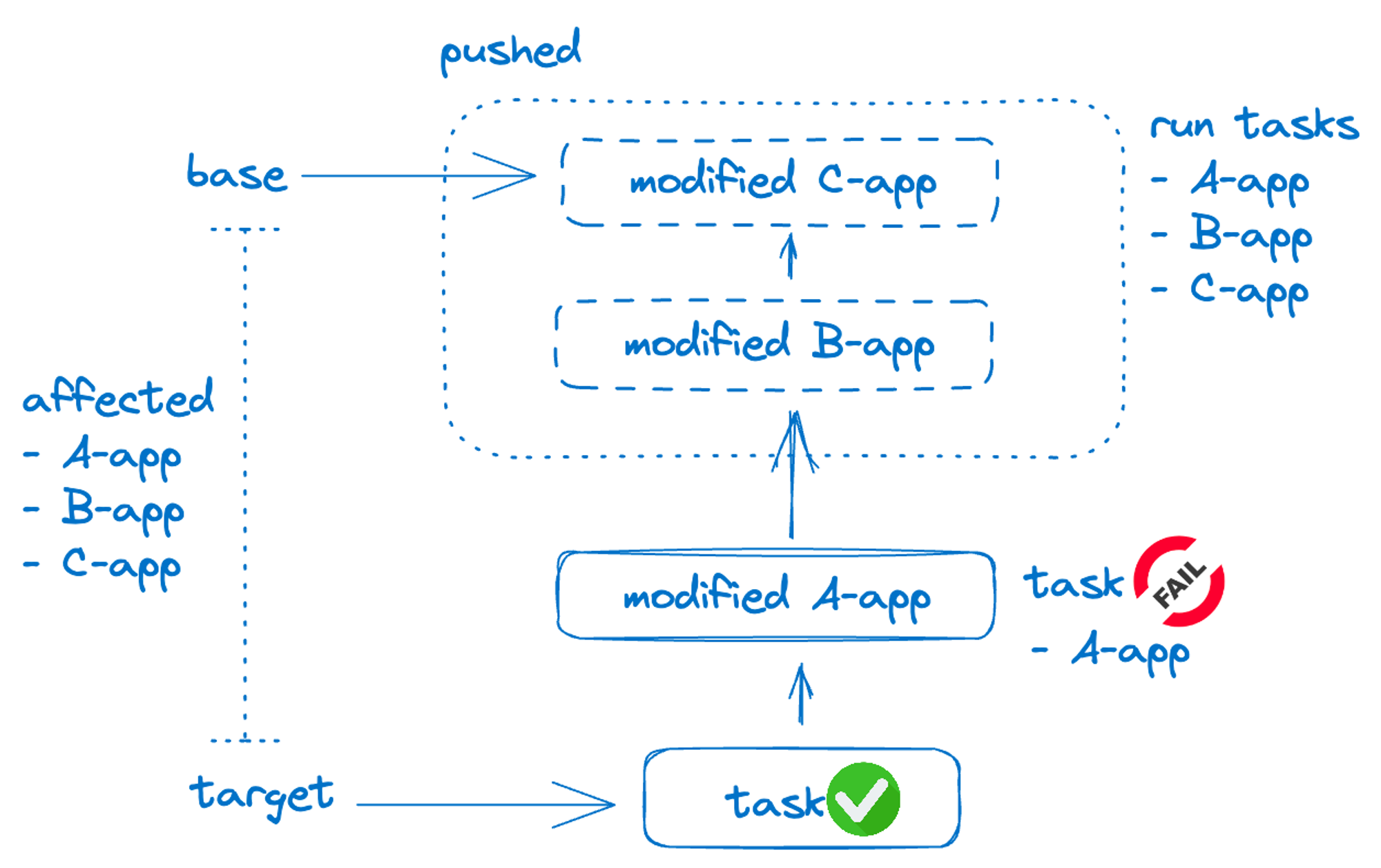
브랜치의 커밋 push는
마지막으로 성공한 버전과 현재 버전의 차이 를 알면 이미 성공한 태스크는 다시 수행 할 필요없이 변경된, 필요한 태스크들만 수행이 가능합니다. github actions의 경우 마지막으로 성공한 태스크를 알 수 있어 비교적 세팅이 간단합니다. 하지만 bitbucket pipeline의 경우 기본적으로는 마지막으로 성공한 버전을 알 수 없습니다. 따라서 base 브랜치와 target 브랜치의 공통 조상 SHA를 찾아 해당 SHA와 비교하여 affected를 판단하게 하였습니다.
- ANCESTOR_SHA=$(git merge-base HEAD origin/dev) - echo $ANCESTOR_SHA - npx nx affected --target=lint --base=$ANCESTOR_SHA --parallel=3 - npx nx affected --target=stylelint --base=$ANCESTOR_SHA --parallel=3
완벽하진 않지만 대부분의 비효율은 리모트캐싱으로 상쇄가 되기 때문에 크게 불편함은 없었습니다.
2. 디팬던시 체인을 고려한 패키지 분리
도메인, 패키지의 성격, 공통으로 사용되는가, 의존성을 갖게되는 경우가 빈번한가 등을 고려하여 전략적으로 패키지를 분리해야 합니다. 그렇지 않으면 사이드 이펙트를 발생하지 않고 실제로 영향을 받지 않는 패키지들도 지속적으로 영향받는 패키지로 고려될 수 있기 때문입니다.
모노레포를 관리하다 보면 종종 발생하는 경우가 “나는 전혀 관련없는 a를 수정하였는데 왜 B,C,D 패키지가 다시 빌드 되는거지?” 입니다. 예를들어 A라는 패키지에 a와 b라는 함수를 export 하고 있고 B,C 패키지 각각에서 a를 import 하여 사용하고 있다고 가정해보겠습니다. a에 변경이 있다면 B,C도 영향을 받고 이것은 매우 자연스럽습니다. 하지만 B,C패키지가 사용하지 않는 b가 수정된다거나 B,C는 전혀 사용하지 않지만 A 패키지에 변경이 발생하면 어떨까요? 이또한 A패키지가 변경되었기 때문에 A패키지를 의존하고 있는 B,C는 영향을 받게 됩니다.
모노레포를 관리하고 운영할 때 개인적으로 이 부분이 가장 어려운것 같습니다. 완벽하고 아름다운 추상화가 힘든것 처럼 항상 애매한 회색영역이 발생하고 그때는 옳았는데 지금은 틀린 경우가 많기 때문입니다.




Nx의 가이드를 참고하여도 완벽하게 같은 컨셉으로 적용하기가 쉽지 않습니다.
3. 수행한 적 있는 테스크는 수행하지 말기
이전에 이미 성공적으로 수행한 작업은 빌드 시간을 줄이기 위해 다시 수행할 필요가 없습니다. 대신, 이전 빌드에서 캐시된 결과를 활용하거나 리모트 캐시를 이용하여 빌드 시간을 대폭 줄일 수 있습니다. 이전 결과를 저장하고 활용하는 것이기 때문에, 이전 결과가 변경되었다면 해당 작업은 다시 수행해야 합니다.
이전 결과를 저장하고 활용하는 방법은 CI/CD 파이프라인에서 매우 효과적입니다. 이전 빌드에서 캐시된 결과를 활용하면 빌드 시간을 단축할 수 있습니다. 또한, 원격 캐시를 이용하면 여러 명이 함께 작업할 때 빌드 시간을 더욱 줄일 수 있습니다. 따라서, 이전 결과를 저장하고 활용하는 것은 모노레포 CI/CD 파이프라인에서 시간을 단축하는 가장 효과적인 방법 중 하나입니다.
대부분의 모노레포 툴은 input(key)에 대한 output(value)을 설정할 수 있고 캐싱을 도와 줍니다. 또한 Nx와 Turborepo와 같은 툴들은 리모트 캐싱을 제공 합니다. 모노레포의 규모가 어느정도 이상 커지면 리모트캐싱의 유무로 생산성의 엄청난 차이가 납니다. 가장 간편하고 편한것은 Nrwl이나 Vercel에서 제공하는 리모트캐싱 서비스를 사용하는것이겠지만 비용의 절감을 위해 S3 버켓을 이용해 리모트캐싱 처리를 하였습니다.


... "tasksRunnerOptions": { "default": { "runner": "@pellegrims/nx-remotecache-s3", "options": { "cacheableOperations": [ "build", "lint", "stylelint", "test", "e2e", "build-storybook", "build-custom-server" ], "bucket": "BUCKET_NAME", "region": "ap-northeast-2", "readOnly": false, "cacheDirectory": ".nx-cache" } } }, ...

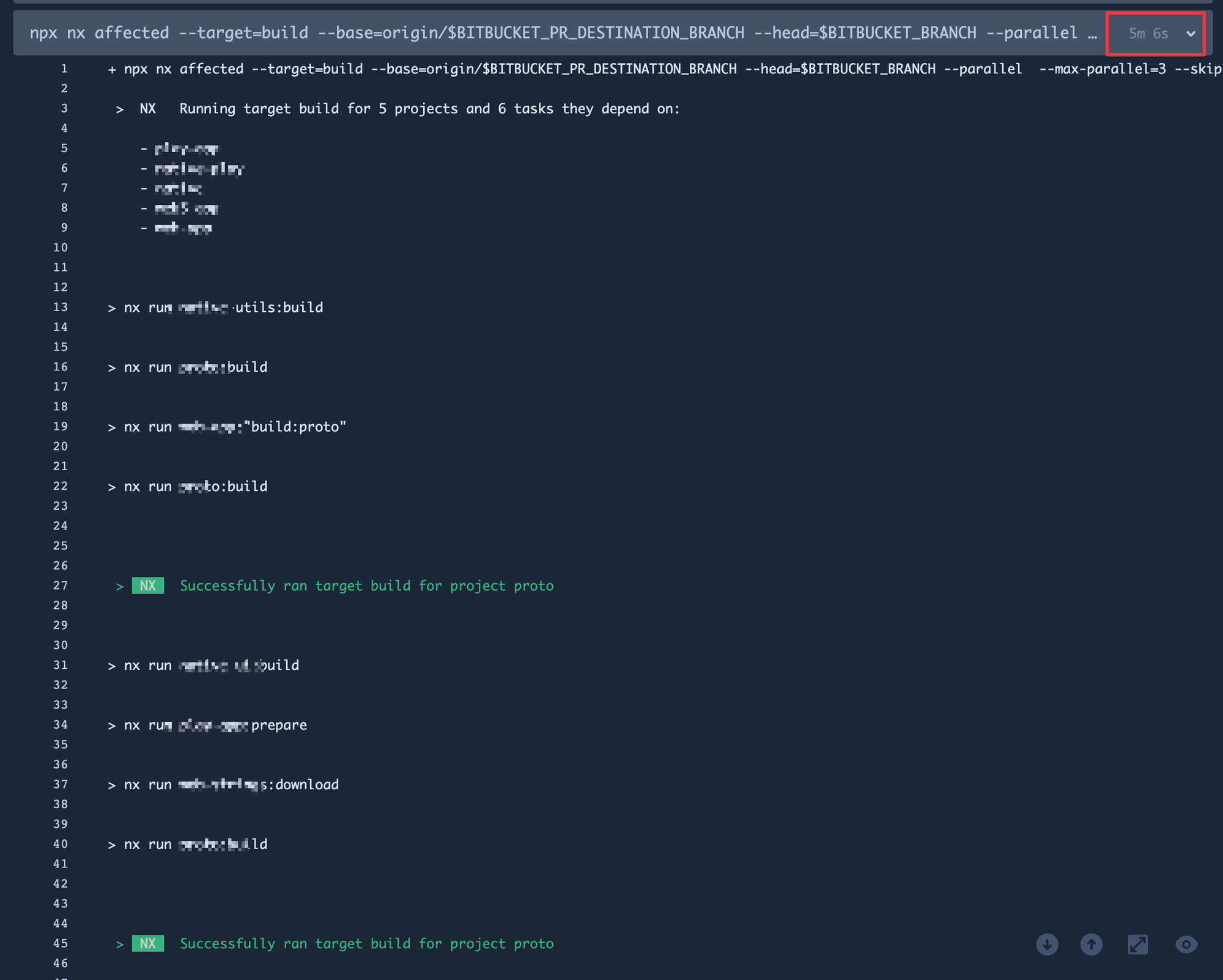

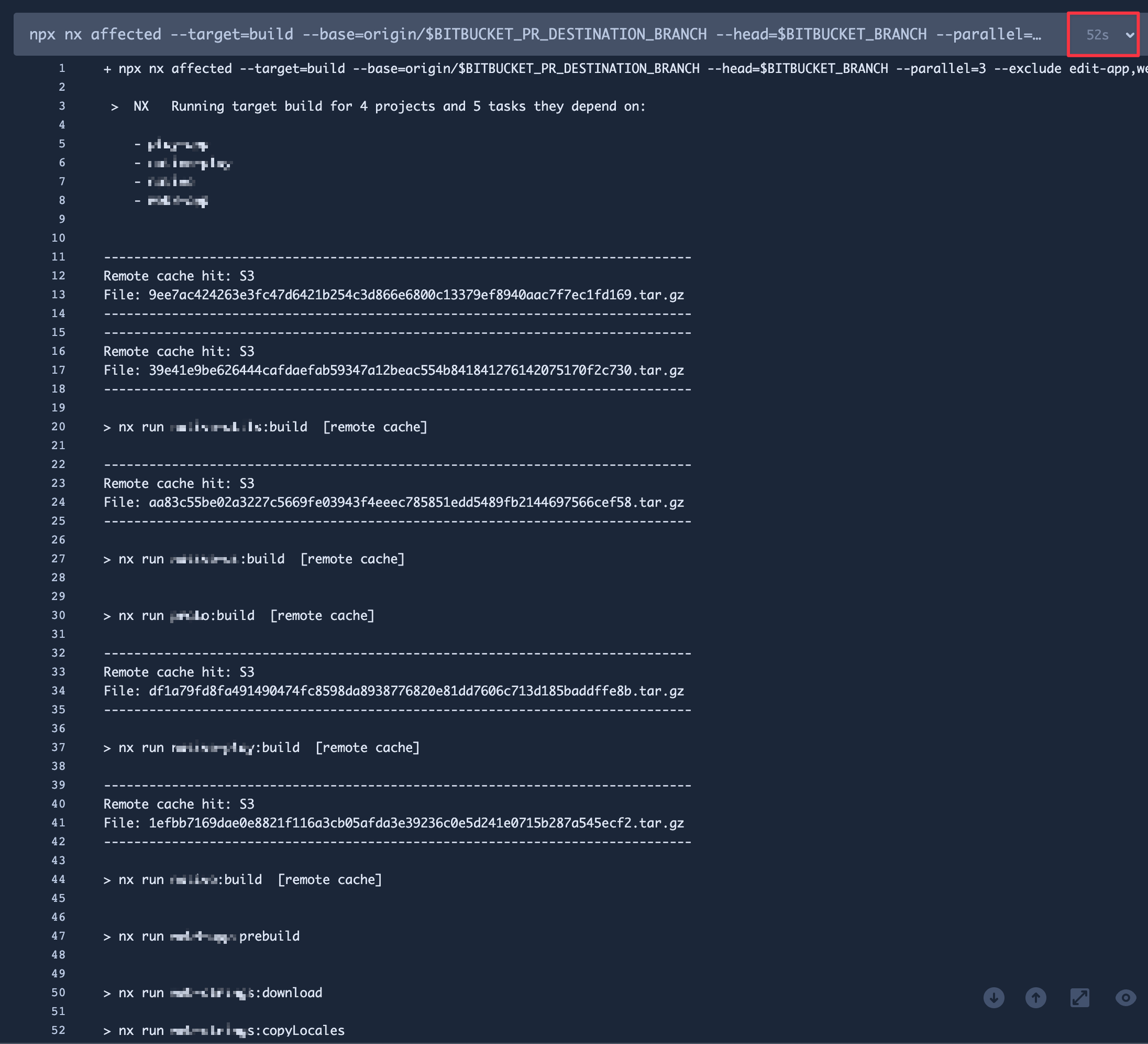
같은 상태도 아니고 태스크의 개수도 다르기 때문에 정확한 비교는 어렵지만, 많은 차이가 있습니다. 태스크의 개수가 많을수록 그 차이는 더 큽니다. 대규모 모노레포를 운영하기 위해서 캐싱 전략은 선택이 아닌 필수입니다.
4. 병렬/분산으로 태스크를 수행하기
태스크를 병렬 또는 분산하여 수행하면 빌드 시간을 대폭 줄일 수 있습니다. Nx를 사용하면 빌드 작업을 분할하여 여러 개의 노드에서 병렬로 실행할 수 있습니다. 이렇게 함으로써, 빌드 작업을 더욱 빠르게 수행할 수 있습니다.

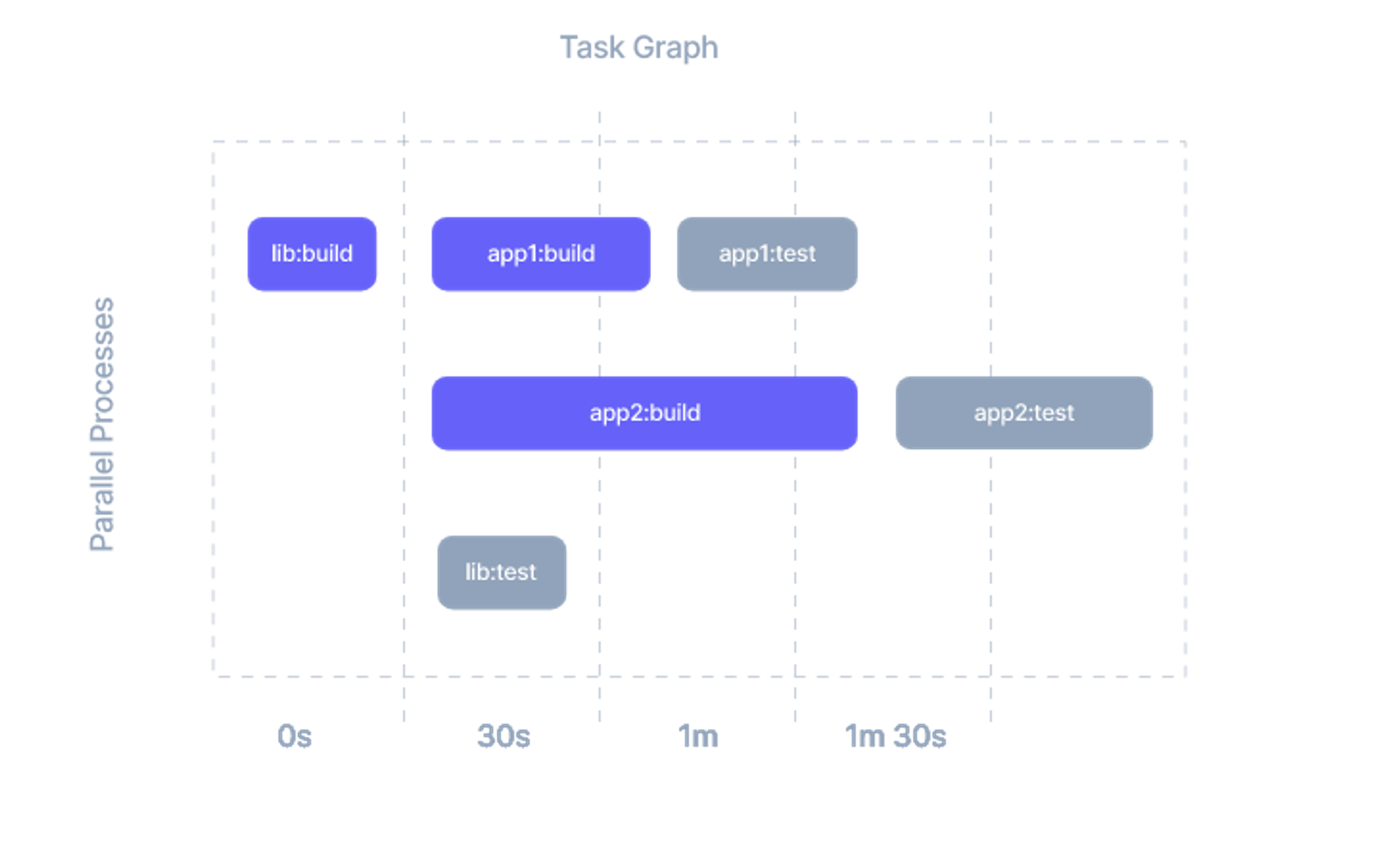

5. 레포 크기 줄이기와 디팬던시 캐싱 전략 세우기
패키지 매니저의 발전으로 zero-install, PnP 등의 장점을 취할 수도 있습니다. 하지만 이를 VCS에서 관리하면 레포의 크기를 증가시켜 상황에 따라 CI 환경에서 더 비효율적일 수 있습니다. 빗버킷 파이프라인의 경우 각 스텝(노드)마다 별도의 인스턴스가 돌아 매번 새로 레포를 클론합니다. ZEP의 경우 모노레포가 급속도로 거대해지면서 최악의 경우 클론의 depth를 줄여도 레포를 클론하여 셋업하는 시간만 50초~1분 가까이 걸리기 시작하였습니다. 거기에 추가적인 캐싱들과 패키지 매니저의 링킹 시간까지 합치면 아무런 태스크를 수행하지 않고 단순히 태스크를 위한 셋업에만 2~3분의 시간이 소비되었습니다. 셋업 자체에 시간이 많이 소모되기 때문에 파이프라인의 스텝을 나누거나 병렬적으로 태스크를 수행하기보다는 하나의 스텝에서 모든 태스크들을 순차적으로 수행하였는데, 그러다 보니 단순한 스크립트를 하나 실행하기 위해서도 몇 분이나 기다려야 되는 상황이 발생하였습니다.
따라서 레포 레벨에서 artifacts나 캐시들을 버전 관리하는 것이 아니라 CI 환경에서 선택적으로 필요한 캐시를 다운로드하여 레포의 크기를 줄이는 것이 훨씬 유연하고 병렬적인 작업에도 이점이 있다고 판단했습니다.

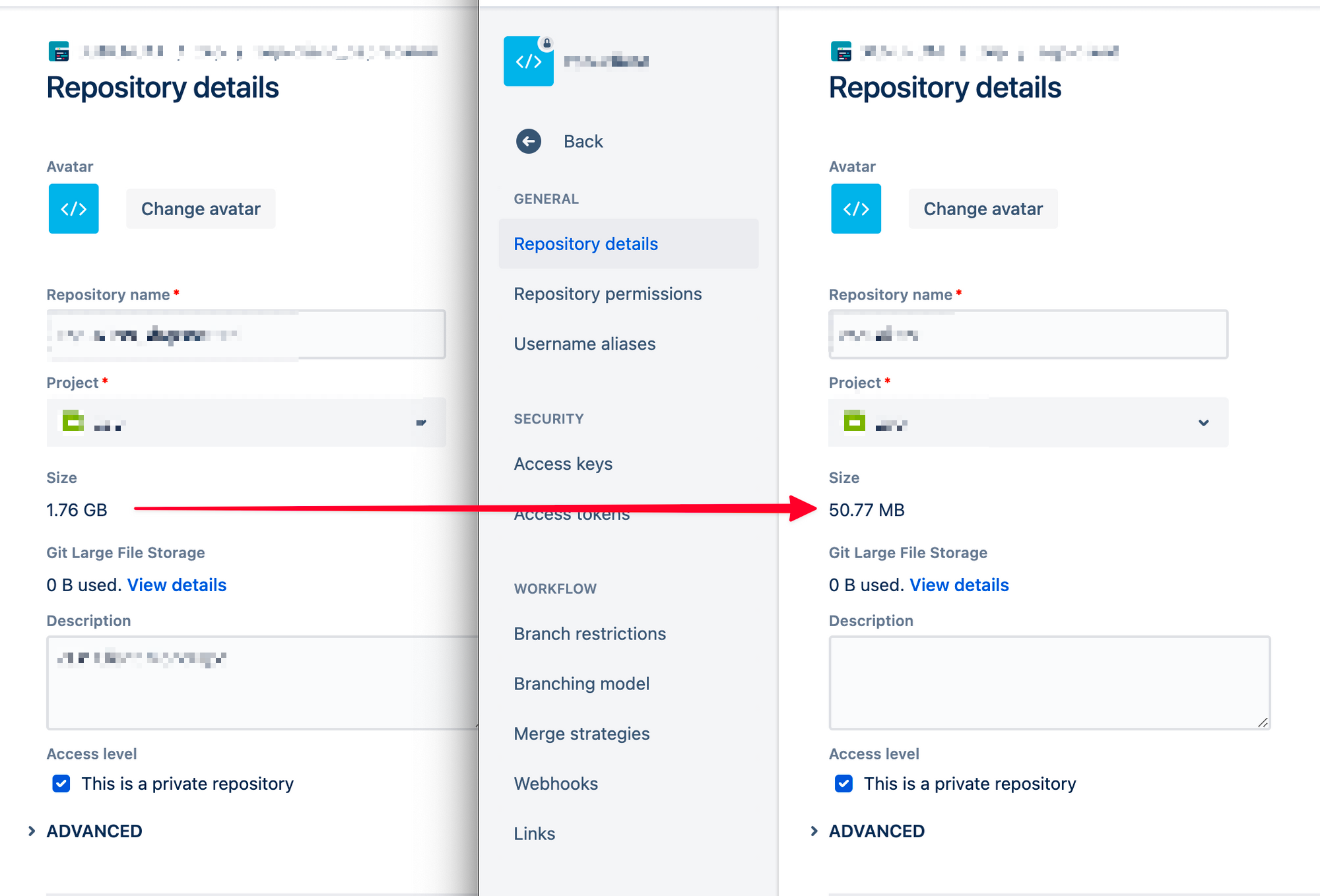
무조건 매 스텝마다 새로 시작해야되는 빗버킷 파이프라인의 제한적인(괴랄한) CI/CD 환경 때문이기도 하지만 레포의 크기를 줄이고 각 스탭에서 필요한 캐시를 로드 하여서 훨씬 유연하고 빠르게 테스크를 수행할 수 있었습니다.
결론
제한된 환경에서 여러 아이디어와 가설을 테스트하고 적용하여 CI/CD에서 오는 병목과 스트레스를 줄일 수 있었습니다. 이 다섯 가지 항목들을 각자의 환경에 맞게 고민하고 개선한다면, 어떤 환경에서든 CI/CD 파이프라인에서 오는 많은 문제를 해결할 수 있으며, 모노레포의 장점을 극대화할 수 있다고 생각합니다.